2026's Easter Potpourri
📍 Cambridge, EnglandAssorted notes4/4/26: Moved URL from 2026-spring-potpourri to 2026-spring-notes.
4/4/26: Amended a typo.
Some notes from before Easter.


Coolify
I'm using Coolify to manage services on my home AI rig. It's pretty good. I like it a lot. If you can use something like the AWS console, Coolify should be familiar to you.
I keep my ML notebooks on there, I have a copy of Label Studio on there, and I also host a Supabase on there too.
There are some sharps, mind.
-
For local services I keep the box on Tailscale. My advice is to set up Tailscale on that box first, then set up Coolify. You probably don't need tailscale on a per-container basis (but if you do, you can use the Client Service as a separate service in your project to keep services on separate tailnets.
-
Don't use sslip.io. Keep a local service behind Tailscale, and when you set up a service and expose it, set it up using
<your-hostname-on-tailnet>:<port>, and give it a few minutes to propagate. -
I would not expose Coolify on the open internet. I would only allow access to it on a VPS from either an SSH connection (using a tunnel) or through Tailscale.
Overall, can recommend. If you want to do the homelab thing, get a used workstation, put Ubuntu server on it, install Tailscale, then install Coolify.
If you don't want to use Tailscale, you can use a Cloudflare tunnel and your own domain name.
The perfect USB-C cable
This very much falls under the "minutiae" label but worth sharing.
Riding motorcycles and using a motorcycle as a primary mode of transportation makes you acutely aware of how much space things take up.
I don't like carrying many cables. They tangle, they're not always the right sort, they take too much space. I have searched for the perfect cable and I think I have found it.
It's a all-in-one cable with USB-A and USB-C one end, and USB-C and ThunderBolt the other. The cable's good for 100W of power, meaning I can charge a laptop with it. It's in a bright colour so I can easily see it. It's not too long (I don't like long cables because they tangle), and it even comes with a pleather cable tidy so I can roll it up.
The slow ones now will later be fast
Apple's been making good moves since the Apple Intelligence fiasco. Apple's stuff is far nicer to use for AI engineering than AMD and Nvidia. Apple can do a trick what is otherwise unavailable to AMD and Nvidia: shared memory.
My RTX-powered AI server has about 16GB of RAM free on a given day (out of 32). I would love to be able to shunt some AI model stuff to that RAM but I can't because VRAM and RAM are different architectures. Meanwhile, a Mac Mini with a recent chipset (M2 and later) can just chop and change and treat VRAM and RAM as the same.
Supabase for GIS
I have used PostgreSQL and PostGIS for years at this point, but both of those things can be a bit of an ogre to DBA. In the absence of easy DBA tooling for both of those things, I opted for SpatiaLite, which functions as an add-on to SQLite databases. There are problems here: you need to enable WAL manually if you want multiple connections, and there are some SQLite quirks (like autoincrement being somewhat slow), but for the most part, it worked reasonably well.
For my personal GIS datastore, I'm starting to use Supabase, which can be viewed of as a self-hosted Firebase (or database-as-a-service platform). It's built on PostgreSQL, but handles a lot more, like storage and auth.
There's a PostGIS
extension which
is great. You just enable it. No more apt install postgis dance, no more using
the postgis/postgis Docker image, just one click. Neat!
I'm used to having queries run against databases (and not using sprocs), but I see the benefit.
from typing import NamedTuple
import db
class NearbyRestaurants(NamedTuple):
id: str
name: str
lon: float
lat: float
dist_meters: float
def get_nearby_restaurants(lon: float, lat: float) -> List[NearbyRestaurants]:
sql = '''
select
id,
name,
ST_X(location::geometry) as lon,
ST_Y(location::geometry) as lat,
ST_Distance(location, ST_Point(%(lon)s, %(lat)s)::geography) as dist_meters
from
gis.restaurants
order by
location <-> ST_Point(%(lon)s, %(lat)s)::geography;
'''
ret = None
with db.connect() as conn:
cur = conn.cursor(row_factory=class_row(NearbyRestaurants)
conn.execute(sql, {'lon': lon, 'lat': lat})
ret = conn.fetchall()
return ret
If I wanted to return another column from gis.restaurants, how many places
do I have to update? Is it just in the database? Do I need to add more columns
to a nest of SQL queries in the application?
Compare to a sproc.
create or replace function nearby_restaurants(lon float, lat float)
returns table (
id text,
name text,
lon float,
lat float,
dist_meters float
)
set search_path = ''
language sql
as $$
select
id,
name,
ST_X(location::geometry) as lon,
ST_Y(location::geometry) as lat,
ST_Distance(location, ST_Point(lon, lat)::geography) as dist_meters
from
gis.restaurants
order by
location <-> ST_Point(lon, lat)::geography;
$$;
From here I can just use the supabase client library to call the sproc.
const { data, error } = await supabase.rpc('nearby_restaurants', {
lon: -1.946713,
lat: 50.807313,
})
I'm quite impressed with Supabase. I've tried their hosted offering and it works quite well. It does what Firebase used to do. If you want one step above PocketBase this is a good choice.
Some tips:
-
Don't dump everything in the
publicschema. Use different schemas for each project. I have<project>and<project>_stagingfor main and staging tables. I keep GIS data ingisand its staging equivalent (the dumping ground prior to processing) ingis_stagingfor example. -
Use row level security. It's PostgreSQL's best feature. Column level security's also pretty good. Both save having a nest of
where user_id in (select user_id from users where 'authorised' in users.permissions)stuff in every query. -
I wouldn't expose PostgreSQL's ports to the outside world except in extremis. I would instead tunnel through SSH.
Explain your vision model
It's all fine and well having your usual precision/recall curves, but can you really explain your vision model in visual terms?
I like to see Class Activation Maps. I find these to be most useful when demonstrating occlusion between classes.
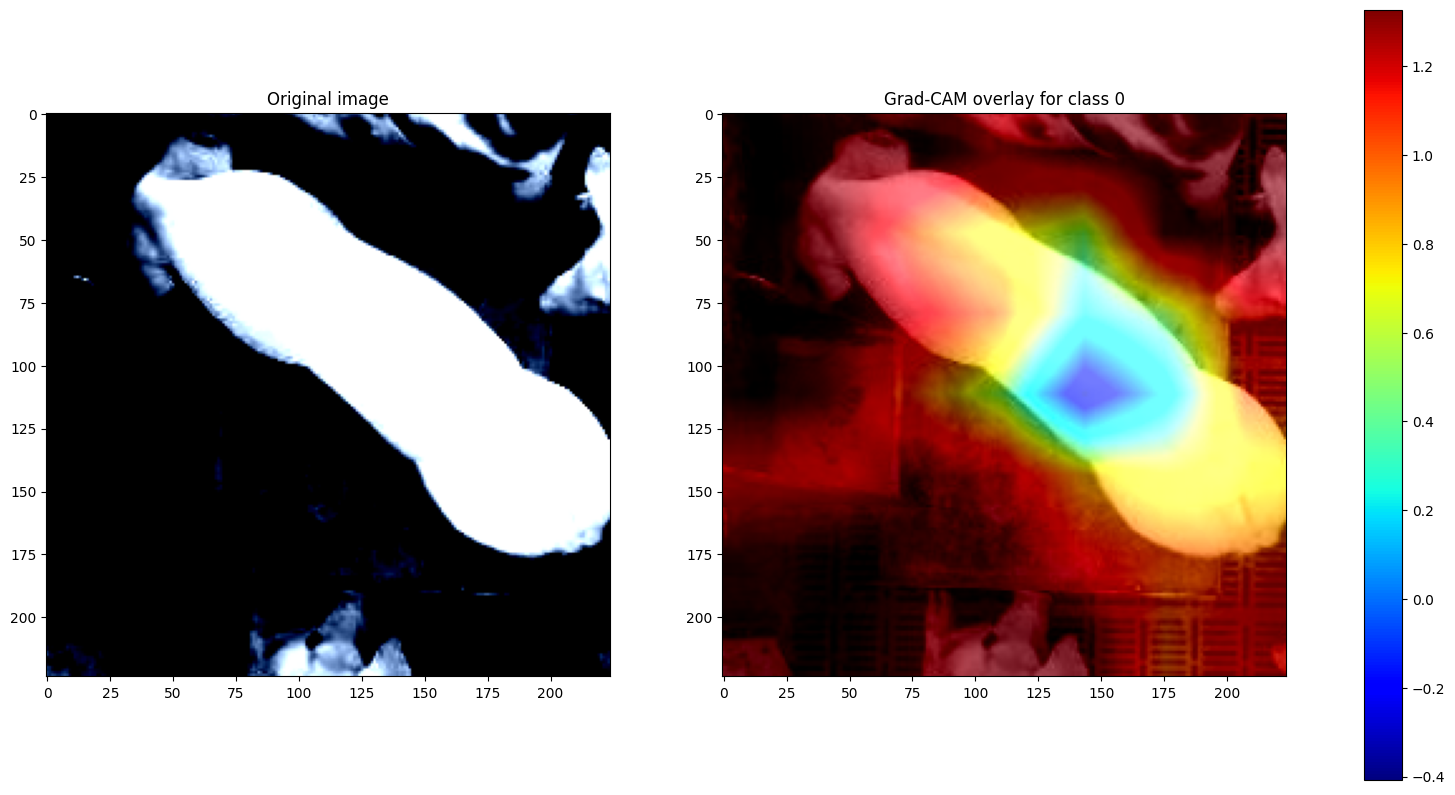
Here's a freebie, my implementation of the Grad-CAM paper.
import torch.nn.functional as F
def grad_cam(model, target_layer, x, class_idx=None):
activations = None
gradients = None
def forward_hook(module, inp, out):
activations = out
def backward_hook(module, grad_input, grad_output):
gradients = grad_output[0]
fwd_handle = target_layer.register_forward_hook(forward_hook)
bwd_handle = target_layer.register_full_backward_hook(backward_hook)
def remove_hooks():
fwd_handle.remove()
bwd_handle.remove()
model.zero_grad()
model.eval()
logits = model(x)
if class_idx is None:
class_idx = logits.argmax(dim=1).item()
score = logits[:, class_idx].sum()
score.backward(retain_graph=True)
weights = gradients.mean(dim=(2, 3), keepdim=True)
camap = (weights * activations).sum(dim=1, keepdim=True)
camap = F.relu(camap)
camap = camap - camap.min()
camap = camap / (camap.max() + 1e-8)
remove_hooks()
return camap[0, 0].detach().cpu(), class_idx
x = read_image()
m = Model()
cam, class_idx = grad_cam(m, m.features[-1], x)
Some tinkering may be required for different architectures (I know MobileNet works slightly differently, and Vision Transformers need different approach entirely).
Rugpull
Anthropic burns $5.2bn for a product with $9bn turnover and OpenAI burns $8.5bn for a $20bn turnover. At some point Intelligence-as-a-service companies will have to raise their per-token prices.
How long will it be before the great AI rugpull?
Once all the boring industries like finance and insurance have dropped all junior positions and are hooked on cheap intelligence and once the AI companies are listed entities on the NASDAQ, expect per-token costs to increase. For Anthropic to break even, they would have to 5x to 10x per-token costs.